
|
Сервер зависает с критической ошибкой и иногда перестраивает массив
Периодически зависает машина, не могу понять причин. Windows Server 2008 R2 в качестве КД, DHCP, SQL и 1С (так уж сложилось, что без HV). Марка сервера: HP PriLoant ML110 G6. 2 х 120 гБ родных HDD массивом RAID-1 (mirror).
 Цитата:
Куда копать, как избежать зависаний? |
Цитата:
|
Цитата:
|
выполните действия по анализу BSOD.
А то, что у вас верификация начинается после загрузки, то это нормальное явление. RAID должен же проверить что у него всё в порядке. |
Цитата:
Какой-нибудь диск сыпется(лампочка должна показывать), может быть. Обратитесь в НР за консультацией. |
Цитата:
|
Цитата:
|
Цитата:
|
Цитата:
А если при загруженной ОС, то уж по крайней мере без каких-либо внешних подключений. |
Цитата:
|
Цитата:
Хотя может это и сбой памяти или чего-то другого. |
alef2474, в моём понимании, есть BSOD, после которого рейд восстанавливается. Причины BSOD не ясны.
|
Цитата:
|
Цитата:
|
Прошу прощения за задержку с ответом. Дамп пока выложить не могу, т.к. не нашел самого файла. Сейчас включу запись дампов согласно этой инструкции (картинка)
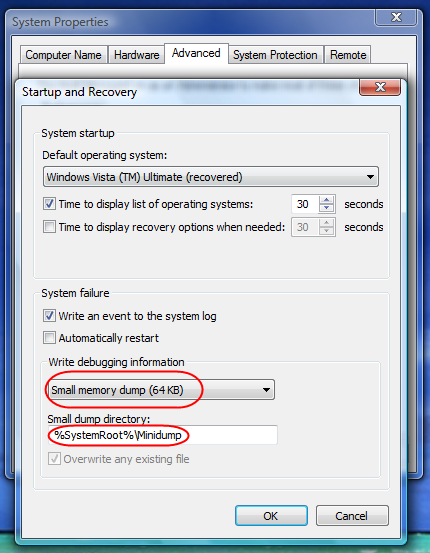 и создам одноименную папку в "../windows/" Разговаривал по теме на мелкомягком форуме, ссылка, если кому будет не лень, в общем итоге нарвались на сообщения от источника Storage Agent: Ошибки 1216: Drive Array Physical Drive Status Change. The physical drive in Slot 0, Port 1I Box 1 Bay 1 with serial number "WCAT1F275051 ", has a new status of 3. (Drive status values: 1=other, 2=ok, 3=failed, 4=predictiveFailure, 5=erasing, 6=eraseDone, 7=eraseQueued) [SNMP TRAP: 3046 in CPQIDA.MIB] И предупреждения 1200: Drive Array Logical Drive Status Change. Logical drive number 1 on the array controller in Slot 0 has a new status of 5. (Logical Drive status values: 1=other, 2=ok, 3=failed, 4=unconfigured, 5=recovering, 6=readyForRebuild, 7=rebuilding, 8=wrongDrive, 9=badConnect, 10=overheating, 11=shutdown, 12=expanding, 13=notAvailable, 14=queuedForExpansion, 15=multipathAccessDegraded, 16=erasing) [SNMP TRAP: 3034 in CPQIDA.MIB] Предполагаю, что Recovering происходит не просто так. С одной стороны, если судить по картинке, то все в порядке:  С другой - собираюсь выключить проблемный ЖД и покрутить недельку-другую "на одном крыле", в это время прогнать Викторией крыло второе. Касаемо зависушек, стоит "автоматически перезагружаться". |
Цитата:
|
Цитата:
|
Цитата:
Смените - один раз перестроится и успокоится. |
110 сервер 6-го поколения ну сильно начального уровня, не стоит ожидать от него чудес самодиагностики. Если агент сказал что recovering, то естественно вы видите статус ОК. Посмотрите смарт атрибуты, скорее всего жесткий диск пора выкидывать. От контроллера b110 так же не стоит ожидать уровня работы ентерпрайз. Он сделан на основе бюджетного intel ich10, со всеми вытекающими. Для серверов 100-серии почти нормально видеть бсод при проблеме с дисками, его задача защитить данные от потери, а не продолжить работу. А почему "почти", потому, что это зависит от прошивок дисков и контроллера и драйверов на последний. Если вам религия не позволяет менять диск пока он не вышел из строя "совсем", обновите микрокоды и драйвера и скорее всего будете видеть такие ошибки в логах без бсода, а просто с замедлением работы сервера, которое тоже нормальное явление для серверов начального уровня и сата дисков.
Вообще это и есть одна из принципиальных разниц оборудования начального уровня и сегментов выше, последние бы в большинстве случаев не стали делать recovering, а сразу исключили сбойный диск из работы. |
| Время: 05:30. |
Время: 05:30.
© OSzone.net 2001-