
|
Удаление дубликатов строк из текстового файла со сравнением по две строки
Доброго времени суток всем.
Знаю что тема уже изъезжена, но готового решения найти не получается. Есть плейлисты (по сути текстовые файлы), при их создании может получаться большое количество дублирующих строк. Например: Код:
#EXTINF:0, 1+1Пересмотрел кучу различных скриптов, сам пробовал батники писать, но все они считывают по одной строке и в выходном файле может получится к названию канала несколько адресов или наоборот. К примеру такой батник: Код:
@echo offКод:
#EXTINF:-1 group-title="Познавательные",Brodilo.TVДругие скрипты делают аналогично. Они сравнивают по одной строке. Может кто подскажет как реализовать сравнивание строк попарно, чтобы не нарушалась структура плейлиста ? Премного буду благодарен за помощь. |
Цитата:
Код:
$aContent = Get-Content -Path 'C:\Мои проекты\0266\0001.txt'Цитата:
|
Iska, спасибо! Да, выходной файл должен быть именно таким. Но у меня Ваш код почему-то не срабатывает. Входной файл остаётся без изменений.
P.S. Мои извинения, всё работает, это я с запуском затупил. Сейчас запуская скрипт батником: Код:
@echo offНо есть некоторые нюансы. Скрипт ps1 нормально читает файлы только в кодировке ANSI, а в выходном файле кодировка OEM866 (это говорит AkelPad, а Notepad++ определяет как ANSI). Можно как-то переделать на UTF-8 ? А то на выходе, если в входном файле есть кавычки типа: Код:
ТРК «Киев»Код:
ТРК <Киев> |
Iska, (ради спортивного интереса) задачу можно решить короче через (MINGW|Cygwin|WSL):
Скрытый текст
Код:
sed 'N;s/\n/ - /' input.log | sort | sed 'N;/^\(.*\)\n\1$/!P;D' | sed 's/ - /\n/g'Можно, правда, еще короче: Скрытый текст
Код:
sed 'N;s/\n/ - /' input.log | sort | uniq | sed 's/ - /\n/g'Если лог большой, лучше через parallel, а еще лучше и вовсе на чистом perl (также однострочник). Но это дело вкуса. |
Цитата:
Код:
gc test.txt -r 2|%{"$($_[0])`n$($_[1])"}|sort -uni |
YuS_2, ReadCount ведь уже установлен в пару, зачем там цикл? Просто select -u:
Код:
gc input.log -r 2 | select -uКод:
gc input.log -r 2 | sort | select -u |
Ребята, спасибо всем !
Но вопрос с кодировкой так и остался. Входной файл/файлы в utf-8 и после скрипта, предложенного ув. Iska, с русскими символами на выходе беда, крякозябры выходят. Сортировка в тексте не обязательна, главное удаление дублей парных строк. С остальными скриптами не совсем разобрался, как их запускать. |
Код:
gc input.log -encoding utf8 ...Цитата:
|
Цитата:
Цитата:
Код:
gc test.txt -r 2|sort -u |
С кодировкой и выводом всё получилось.
Огромная благодарность всем за помощь! |
Цитата:
|
По ходу работы со скриптом, выяснились некоторые нюансы. Для скрипта, предложенного ув. Iska:
Цитата Iska: Код:
$aContent = Get-Content -Path 'C:\Мои проекты\0266\0001.txt'требуются идеальные пары строк: название канала - ссылка. И соответственно чётное количество строк. В противном случае строки могут перемешаться, и ссылки не будут соответствовать. Бывает попадаются файлы с различного рода мусором между строк. К примеру: Код:
#EXTINF:-1 ,Первый каналМожно ли, перед выполнением основного кода скрипта, как-то удалить всё, что не соответствует парам канал - ссылка ? Регулярным выражением или дополнительным кодом в скрипт. То есть первая строка название канала, обязательно начинающееся на #EXTINF, вторая строка - обязательно ссылка (могут быть http; https; rtmp; mms; rtmpe; udp). Всё что не соответствует таким парам нужно удалить. |
Составил такой RegExp:
Код:
^(#EXTINF.*[^\n\r]+\r?\nhttps?:\/\/[^\n\r]+\r?\n?|#EXTINF.*[^\n\r]+\r?\nrtmp:\/\/[^\n\r]+\r?\n?|#EXTINF.*[^\n\r]+\r?\nmms:\/\/[^\n\r]+\r?\n?|#EXTINF.*[^\n\r]+\r?\nrtmpe:\/\/[^\n\r]+\r?\n?|#EXTINF.*[^\n\r]+\r?\nudp:\/\/[^\n\r]+\r?\n?) |
Код:
for ($i, $arr = 0, (gc input.log); $i -lt $arr.Length;) {Код:
#EXTINF:-1 ,Первый канал |
greg zakharov, спасибо большое!
Но у меня почему-то не получается запустить скрипт, выдаёт ошибку компиляции: 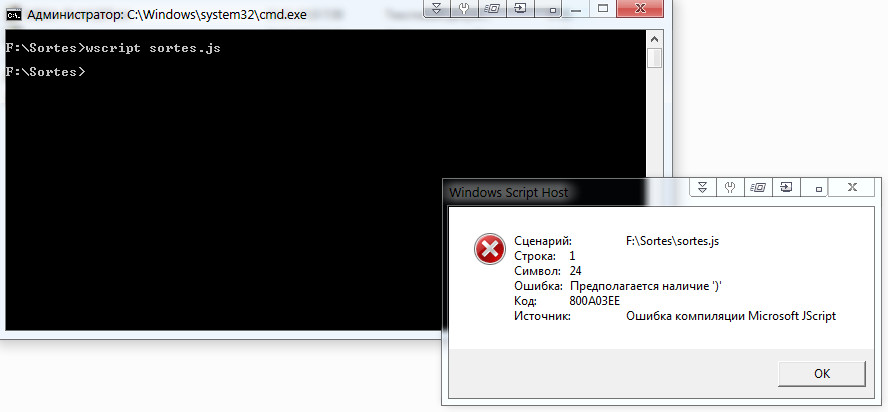 |
Uragan66, ничего удивительного: вы пытаетесь запустить сценарий pwsh как WSH, - последнему ничего не известно о синтаксисе PowerShell.
|
greg zakharov, извините, думал, что скрипт нужно запускать как js.
Теперь разобрался... Большая благодарность за скрипт! |
Немного подправил скрипт под свою задачу:
Код:
@(for($i, $arr = 0, (gc .\*.m3u -Encoding utf8); $i -lt $arr.Length;) {Ещё раз большое спасибо всем за помощь! |
Здравствуйте!
Использую, подсказанный ув. greg zakharov, скрипт: Код:
@(for($i, $arr = 0, (gc .\*.m3u -Encoding utf8); $i -lt $arr.Length;) {Но бывает возникает необходимость пускать на вход не один файл, а несколько. Подскажите, пожалуйста, можно ли для обработки скриптом прописать не один файл, а папку с файлами одного расширения ? Буду премного благодарен за ответы и подсказки. |
Цитата:
Код:
gc C:\temp\*.txt |
DJ Mogarych, так не пойдёт для нескольких файлов, сам скрипт написан для обработки только одного файла. Нужно его изменить на multiple, только, увы, я не знаю как.
|
Цитата:
Код:
function set-outfile { |
YuS_2, спасибо большое. Это то, что нужно.
|
Вложений: 1
Привет!Что то пошло не так,помогите пожалуйста понять,на скриншоте во вложении все видно.
|
Alex2010god, у вас старая версия PowerShell, скрипт использует новые возможности. Обновите PoSh до 5.1
|
Вложений: 1
Установил 5.1 никаких изменений кроме того что пропал русский язык(как вернуть рус.яз на место?)
|
Цитата:
В том каталоге, откуда Вы пытаетесь исполнять код (на Вашем скриншоте это каталог профиля текущего пользователя), отсутствует каталог с именем «каталог». |
Благодарю!Далек от программирования - ничего не понял из Вашего ответа(что нужно сделать что бы каталог появился?)...
Как вернуть русский язык для PowerShell 5.1? |
Цитата:
Цитата:
|
В начале скрипта указан адрес:
$aContent = Get-Content -Path 'D:\1\FILMOTEKA.M.C+\F.m3u' просто вписать вместо .\каталог так .\D:\1\FILMOTEKA.M.C+\F.m3u или еще как ни будь? |
Цитата:
Где это видно? Покажите полностью, что Вы запускаете, какая при этом возникает ошибка и главное - что в итоге желаете получить. А применительно к указанному выше скрипту: Код:
function set-outfile { |
Так все же видно на скриншотах(опубликованных ранее в теме,ничего не менял кроме версии ПоверШелл).
|
Цитата:
2. Скрипт лучше показывать в текстовом виде, а не скриншотами... 3. Цитата:
4. Цитата:
|
Если нужны уникальные пары строк, то лучше наверное:
Код:
Get-Content 1.m3u -ReadCount 2 | Sort-Object | Get-Unique |
Цитата:
|
Для меня темный лес,ну попытался и не получилось(зря только версию на русском языке "ПоверШелл" сменил на английскую).
Цель была такова - обработать плейлист IPTV и выявить и удалить дубликаты. Проще было бы батник скрипта сделать(положил в папку с плейлистом,нажал он сам все сделал и выдал готовый плейлист с тем же именем+цифра 01,последующий обработанный плейлист 02 и Т.Д.) На просторах "паутины" нашел программу - без оболочки которая все это делает в один клик(искал неделю или две). |
Цитата:
Здесь существует несколько если: Если плейлист составлен верно и в нем нет ошибок, описанных выше, Если в плейлисте отсутствуют "лишние" строки, как-то, например маркер плейлиста (#EXTM3U) и т.п., Если цель - исключительно только удалить дублирующиеся ПАРЫ строк, то для одного файла, достаточно запустить такой скрипт: http://forum.oszone.net/post-2877089.html#post2877089 Код:
# Здесь в одинарных кавычках необходимо указать свои: путь к файлу и наименование файлаКод:
function delete-marker {В общем, это уже другая задача, под которую необходимо составить перечень условий, т.е. вычленить все возможные "лишние" теги, которые надо либо удалить, либо просто добавить в строку, например (#EXTINF:-1 group-title="Общие",Евроновости), которая изначально может быть представлена так: Цитата:
Цитата:
|
Цитата:
А если проверить ещё и названия каналов на соответствие того, что в ссылках... там вообще мрак... Цитата:
Минимально встречавшиеся кривости (далеко не все возможные, наверное)
Код:
#EXTM3UДолжно получится примерно это: более-менее выправленный лист
Код:
#EXTINF:-1 ,0 - FREE-IPTVПримерный код, возможно неоптимальный. Медленный, но верно работающий... :)
Код:
param ( |
Цитата:
У всех интернет-провайдеров же цифровое тв практически бесплатно, так что не довелось столкнуться с iptv. Цитата:
Код:
param(В общем интересно было поискать уникальные пары, а в самих плейлистах не шарю) |
Цитата:
m3u Цитата:
Цитата:
Вот, валидный и дополненный пример из поста выше: Пример...
Код:
#EXTM3U url-tvg="http://server/jtv.zip" cache=500 deinterlace=1 aspect-ratio=4:3 croppadd=10x10 tvg-shift=0 Цитата:
И кстати, сортировку лучше не по ссылкам делать, ибо часто меняются, а по наименованиям каналов. |
Цитата:
Цитата:
Код:
param(List4-OUT
Код:
#EXTINF:-1 ,0 - FREE-IPTVЦитата:
Так что, видимо, надо сортировать по обоим параметрам. Теперь, по идее, будет работать для любых примеров. |
Цитата:
Многие провайдеры интернета предоставляют своим пользователям и бесплатное ТВ по мультикасту. Нюансов там очень много, но тема не об этом... Sorry за оффтоп |
Цитата:
Но как сделать сортировку по имени канала, если в строке перед названием канала есть дополнительные директивы, к примеру: Код:
#EXTINF:0 group-title="Русские" tvg-id="rossia1" tvg-logo="https://pbs.twimg.com/media/DxnvslfWsAE6Sys.png",Россия 1 HDКод:
#EXTINF:0 group-title="Русские" tvg-id="match-tv" tvg-logo="https://pbs.twimg.com/media/Dxnv4yWW0AArM1C.png",Матч ТВ |
Код:
param( |
Код:
Get-Content 1.m3u -ReadCount 2 | Sort-Object { $_[0].Split(',')[1] } |
Fors1k, к сожалению, Ваш код не подходит для плейлистов, где в обязательном порядке должны считываться по две строки (строка с именем канала и ссылка). Код, предложенный Вами, их перекручивает.
Foreigner, Ваш код строки не перекручивает, но и алфавитной сортировки, именно по имени канала, не возвращает. |
Только что запустил код. И мой, и от Foreigner выдает результат, который вы предоставили, как ожидаемый.
|
Fors1k, да, действительно... мои извинения. Пример просто немного неудачный представил.
Но и первый и второй код будет работать только с "чистыми" строками. Если будет, к примеру, директива объявления плейлиста #EXTM3U (самой первой строкой), то скрипты сработают как я выше написал. Попробую после удаления дубликатов запустить. Спасибо! |
Цитата:
Код:
param( |
Fors1k, этот код я пробовал раньше... К сожалению, он работает неправильно.
К примеру, возьмите плейлист: Плейлист
Код:
#EXTM3UВ нём несколько вхождений каналов с одинаковыми именами, но с разными ссылками (к примеру - #EXTINF:-1,A1). Они должны все остаться в листе, но Ваш код оставляет только одно вхождение. К тому же удаляются нужные строки с директивой #EXTVLCOPT. |
Цитата:
Цитата:
#EXTINF:-1,Bridge TV http://ott-cdn.ucom.am/s33/04.m3u8 Покажите как должен в итоге выглядеть этот пример. Похоже, все-таки нужо оставить мне эту затею, так как каждый раз условия конечного результата разные :) |
Попробуйте так, особо не тестировал, но вроде сортирует
Код:
[hashtable[]] $channels = |
Цитата:
К примеру может быть такой плейлист: in_list
Код:
#EXTM3UВ идеале на выходе должны получить: out_list
Код:
#EXTM3Uто есть должны удалиться дубликаты и по именам каналов и по ссылкам на потоки, но при этом структура плейлиста не должна быть нарушена и должны сохраниться директивы #EXTGRP и #EXTVLCOPT Foreigner, к сожалению Ваш код тоже путает строки. Ну да ладно... Пока дорабатываю старый рабочий код, просто почитал новые посты в теме и пришла мысль добавить ещё и алфавитную сортировку по имени канала... |
Цитата:
Цитата:
Цитата:
Цитата:
А поскольку пока были условия в задаче проверять таки только ПАРЫ строк, то и уникальность проверяться должна именно ПАР строк, а сортировка пар по имени канала, либо по ссылке - здесь вторично. Цитата:
Цитата:
Как и писал выше, необходимы ПОЛНЫЕ условия задачи... а вот это: Цитата:
Цитата:
Например тег: Цитата:
а это: Цитата:
Кроме того, этот тег в более универсальном виде, лучше переместить таки в строку #EXTINF... В общем: Цитата:
Цитата:
Цитата:
|
| Время: 19:41. |
Время: 19:41.
© OSzone.net 2001-